Hierarchical Multi-Task Word Embedding Learning for Synonym Prediction论文翻译
同义词预测的分层多任务词嵌入学习
Hongliang Fei, Shulong Tan, Ping li 百度智能计算美国研究实验室
摘要
同义词自动识别对于以实体为中心的文本挖掘和解释具有重要意义。由于现实生活中语言使用的高变异性,手工构建语义资源以覆盖所有同义词的成本过高,也可能导致覆盖范围有限。尽管有公共知识库,但除了英语外,它们只覆盖了有限的语言。本文以医学领域为研究对象,提出了一种自动加速中文医学同义词资源开发的方法,包括医疗专业人员的形式化实体和最终用户的嘈杂描述。基于分布式词表示的成功,我们设计了一个具有层次任务关系的多任务模型,以学习更多具有代表性的实体/术语嵌入,并将其应用于同义词预测。在该模型中,我们扩展了经典的skip-gram词嵌入模型,引入了一个辅助任务邻词语义类型预测,并根据任务复杂度对邻词语义类型进行分层组织。同时,我们将已有的医学术语同义词知识纳入到我们的词嵌入学习框架中。我们证明,与基线相比,从我们提出的多任务模型训练的嵌入在实体语义相关性评价、邻近词语义类型预测和同义词预测方面有显著的改进。此外,我们还建立了一个包含实体注释、描述和同义词对的大型中文医学文本语料库,为今后在这一方向上的研究提供了参考。
1 引言
同义词预测已经成为以实体为中心的文本挖掘和解释的一项重要任务[28,32]。借助同义词预测,可以将实体的非正式提及规范化为标准形式,这将大大减少终端用户和下游应用程序之间的通信差距。这些例子包括但不限于问答匹配[9],信息检索[39],医学诊断[20]。
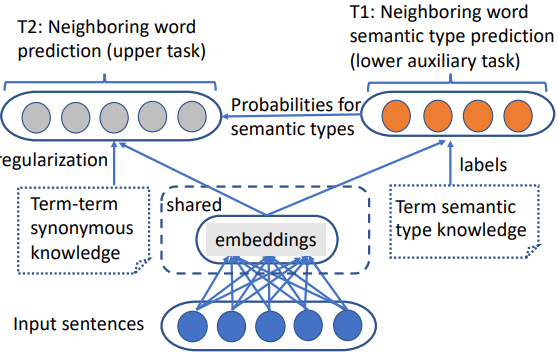
图1:提出的分层多任务词嵌入模型综述。术语的语义型知识和术语同义知识在不同的层次上以不同的方式被利用。
从资源的角度来看,同义词预测的主要困难是语言使用的变异性高[5],而知识库(KB)的覆盖率低[13],尤其是英语以外的语言。例如在中医领域,概念食欲不振(翻译:食欲不振)已经超过20种同义词,但大多数人混肴使用,因为他们所使用的主要是患者没有多少医学知识。尽管可以利用最先进的命名实体识别工具[21]来发现更多的实体,但构建带有注释的标签的数据来进行非正式描述和用于训练同义词这方面只做了很少量的工作。
从建模的角度来看,同义词预测的关键问题是如何学习更有效的实体和描述的表示。有了高质量的语义表示,任何现成的分类器都可以用来预测同义词关系。最近,单词和实体嵌入方法[16,17,23,24]从大型语料库中学习单词的分布式向量表示,已经在数据挖掘社区中流行起来。对于英语,已经提出了一些基于词或字符嵌入的同义词预测方法[11,15,32]。
例如,Wang等人的[32]集成了术语的语义类型知识到词嵌入学习中,并将学习到的嵌入与其他句法特征结合起来用于同义词预测。尽管模型利用了语义类型知识,但它忽略了实体之间丰富的关系信息。Hasan等人[11]使用字符嵌入作为术语特征,将同义词预测任务视为神经网络的机器翻译问题,在给定源项的情况下,通过双向RNN生成目标同义词。这种复杂模型的一个限制是,它需要UMLS[18]中大量的标记数据(同义词对),而中文中没有这样的公共资源。
我们假设,结合语义知识将学习更多有代表性的词嵌入,从而导致更准确的同义词预测。在本文中语义知识既包括实体的语义类型信息,也包括实体之间的语义关联信息。受Søgaard和Goldberg[29]和Hashimoto等人[12]的启发,他们显示出在连续层预测两个日益复杂但相关的任务的能力,我们提出了一个分层的多任务词嵌入模型,如图1所示。在底层,我们引入了一个辅助任务,根据目标词预测邻近词的语义类型。在上层,我们扩展了skip-gram模型[23],以合并实体之间已有的同义词知识和下层任务的结果。这种层次化的结构使得我们不仅可以利用实体、语义类型和语义关系,而且可以在训练阶段相互增强这两个任务。
虽然我们的研究方法是通用的,但中文医学领域的语言使用变异性非常高,语义知识丰富,但知识库覆盖率低。我们的模型也可以应用于任何其他领域,在这些领域,外部知识非常多,语言使用的可变性非常高。实验结果表明,该模型在实体语义关联度评价、相邻词语义类型预测和同义词预测等方面具有较高的准确率。
综上所述,本文的贡献如下:
我们提出了一个层次的多任务词嵌入模型,充分利用医学领域的知识。通过引入邻词语义类型预测的辅助任务,为目标词嵌入提供更多信息。针对该模型,我们设计了一种优化算法,取得了比现有算法更好的性能。
我们从专业医学教科书、维基百科和论坛中收集了大量的中文医学语料库(约10M句子),目的是识别更多非正式医学描述和同义词对。从语料库中,我们识别和注释了151K个医疗实体和描述,涵盖18个类别,185K个高质量同义词对。带注释的数据集将帮助其他研究人员发现更多嘈杂和非正式的医学描述。据我们所知,该语料库是第一个既有实体标注又有同义词标注的汉语基准。
我们将我们的模型应用于400M对医学术语,并获得了约1M以前任何医疗资源中未见过的同义词候选词。新发现的同义词可以丰富已有的汉语知识库。此外,我们对我们的方法进行了深思熟虑的错误分析,为今后在这一方向的工作提供了思路。
2 相关工作
同义词抽取的重要性在生物医学和临床研究领域得到了公认[14,22]。早期的方法通常是非基于神经系统的方法。传统的技术包括使用词汇和句法特征[10],基于双语对齐的方法[31]和术语图[25]上的随机漫步。为简单起见,我们不详细讨论它们。
在基于神经网络的方法中,单词嵌入技术被广泛用于同义词预测[11,15,32]。近年来,通过增强领域语义知识来增强词汇嵌入的研究越来越受到人们的关注。这种增强要么通过在训练阶段添加关系正则化来改变单词嵌入的目标[34,35],要么对训练的单词向量进行后处理以适应语义关系[7]。对于这两种情况,只使用术语-术语关系,但忽略术语的语义类型信息。在表1中,我们总结了相关方法和我们的特点。
.jpg)
表1 每个方法的特征。ST为语义类型,SR为同义关系,PP为后处理,MT为多任务。“x”表示方法具有一定的属性。
在所有基于嵌入的方法中,与我们最相似的是Wang et al.[32]和Yu and Dredze[37]。Wang等人在[32]中,在词汇嵌入训练过程中,将词汇的语义类型作为外标签信息加入。这种半监督的方法使得单词嵌入模型在生成所需单词时考虑所需的类型,这是在同一层次上有两个任务的多任务学习的一种特殊情况。在我们的模型中,我们不仅利用了术语的语义类型,而且还利用了术语-术语同义关系。Yu和Dredze[37]提出了一种关系约束的词嵌入模型,该模型通过最大化所有同义对的对数似然来利用术语-术语同义关系。虽然我们也使用术语之间的同义关系,但我们的工作和他们的工作有两个主要区别。第一个不同之处在于,我们的词嵌入模型是一个分层的多任务学习框架,它的辅助任务是预测词汇的语义类型。第二个区别是,我们采用了不同的正则化策略来强制同义对共享相似的嵌入,而不是最大化它们的对数似然。
另一个相关的研究方向是多任务学习(MTL),它同时学习多个相关任务以提高泛化性能。MTL已被广泛应用于医疗信息学[8]、语音识别[30]和自然语言处理等领域[12,29]。特别地,我们的工作受到了Søgaard and Goldberg[29]和Hashimoto et al.[12]的启发,他们证明了通过考虑语言层次,在不同层次上定位不同任务的优势。例如,Hashimoto等人[12]构建了一个多任务模型,其中任务根据其复杂性递增(如词性标注实体分块依赖解析)。他们的工作和我们的工作的关键区别在于,我们的分层多任务模型不仅解决了两种预测任务,而且还利用了两种类型的语义知识。
3方法
在本节中,我们首先描述原始的skip-gram模型[23],然后解释我们的分层多任务词嵌入模型。在详细介绍之前,我们在表2中概述了本文的表示法。
.jpg)
3.1 skip-gram嵌入模型
skip-gram模型[23]的目标是优化能有效预测给定目标词的邻近词的词嵌入。更正式地说,它使以下目标函数最小化

| 其中xt是目标单词,c是上下文窗口大小。利用softmax函数计算概率p(xO | xi) |
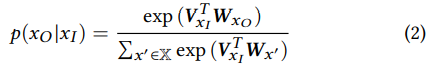
skip-gram模型交替更新V和W,输出隐藏的表示V作为最终的单词嵌入,其中Vi的第i行为单词xi s的嵌入向量。
3.2 分层多任务词嵌入
我们扩展了skip-gram模型[23],引入了邻近词语义类型预测的辅助任务。关键是了解相邻词的语义类型有助于相邻词的预测。例如,在医学领域,症状术语经常被其他症状术语或疾病术语所包围。在本文中,我们假设每个输入句子都被分割成一个单词/短语序列,并对医疗实体进行标注。预处理的优点是,我们可以直接训练嵌入医疗实体和描述,就像其他普通单词一样。
很明显,有三种方法来组织这两项任务。
- 将两个任务并行组织并共享共同的隐藏嵌入层,相当于神经网络中共享隐藏层的普通多任务学习
- 将两个任务分层组织,其中邻词预测任务放置在较低位置,邻词语义类型预测任务放置在较高位置
- 本文提出的层次结构如图1所示。它使邻词预测能够利用邻词语义类型预测和共享词嵌入的结果
我们选择最后一种结构有两个原因。首先,预测邻近单词比预测它们的语义类型更复杂。所有可能的相邻单词集的基数等于词汇表大小,比语义类型的基数大得多。其次,从语言学的角度来看,了解可能的语义类型有助于邻近词预测任务对属于这些类型的词进行集中预测。
在图2中,我们展示了我们建议的模型框架。在训练过程中,首先将目标词及其邻近词输入到输入层进行嵌入查找。同时,利用外部医学知识库(KB)对邻近词进行查询,确定其对应的语义类型。任务T1的训练数据是目标词及其邻近词类型的嵌入。注意,只有相邻的具有有效语义类型的单词(例如红色的单词)才会被输入T1。任务T2的输入是T1的语义类型概率分布和目标词与邻近词嵌入的概率分布的拼接。此外,将目标词的同义词作为外部知识输入T2。
3.2.1 T1:相邻词语义类型预测。
给定输入的单词和它的嵌入向量,这个任务是在一个上下文窗口中预测它的相邻单词可能的语义类型。例如,在图2中,输入术语runny_nose被两个症状术语和一个疾病术语包围,上下文窗口大小为7。这个模型被期望为症状和疾病的语义类型分配更高的概率。
我们将任务T1转换为一个多标签分类问题,其中标签的数量等于语义类型的数量。虽然有很多复杂的多标签分类算法[38,40],但我们使用的是二进制相关[27],即为每个标签独立训练一个二进制分类器。选择二值关联的原因是,当损失函数为宏观平均测度[19]时,二值关联不仅计算有效,而且可以归纳出最优模型。特别地,我们最小化下面的正则化加权交叉熵目标。
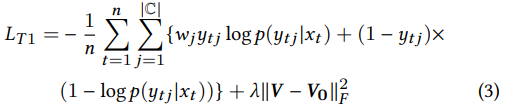
| 其中,当输入单词xt在训练集中有一个类型为cj的相邻单词时,yt j = 1,否则yt j = 0。Wj是cj类的正样本权重,可以作为相反的正负样本比率。条件概率 p(yt j | xt)定义为p(yt j | xt) = σ(UTj Vxt)。V0为上一纪元训练任务T2后的词嵌入,λ为正则化参数。为简单起见,我们省略了公式(3)中的偏差项,尽管我们在实现中包含了偏差项。 |
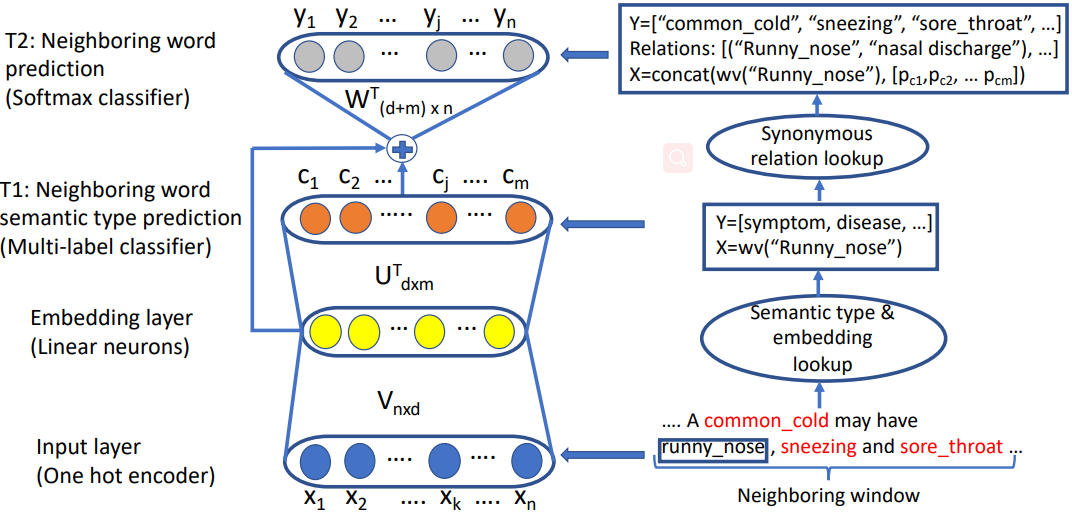
图2 分层多任务词嵌入模型体系结构。注意,这两个任务都可以访问嵌入层。任务T1将使用语义类型信息,而任务T2将使用现有的同义词关系知识。右侧显示了如何将数据输入模型的示例。在这里Runny_nose是目标单词,上下文窗口大小为7。
| (3)中的公式 | V-V0 | 上2下F称为逐次正则化术语[12],它惩罚了当前嵌入参数与从其他任务中学习到的参数的偏差。这样的正则化术语有助于防止参数在切换任务时变化过大,从而稳定训练过程。 |
注意,我们假设每个医学术语只有一个语义类型,这在医学领域是有效的,因为一个医疗实体很少有两个或更多的语义类型。例如,“阿司匹林”是一个药物实体,它不能包含疾病的语义类型。当将任务T1扩展到一个术语可能具有多个多重语义类型的其他领域时,可以使用上下文感知模型,如上下文依赖网络[26]。因为我们的重点是在医学领域,我们不讨论一般案例。
3.2.2 T2:邻近词预测
我们的邻词预测任务方法类似于最近利用先验知识(如释义、同义词)改进词嵌入的工作[7,34,37]。这些方法使用正则化术语修改原始的词嵌入目标,鼓励语义相关的词共享相似的词嵌入。不同之处在于,我们是在多任务环境下解决问题的,而他们的方法都是单任务学习。
特别地,我们用语义类型预测任务T1的结果来增加任务T2的输入,并利用逐次正则化项来促进两个任务参数之间的一定程度的一致性。
让表示与任务T1相关的模型参数。任务T2被最小化的目标如下:
.jpg)
其中S(xt)为来自外界知识的xt的同义词/释义集,fT 1(xt)为xt的邻域语义类型预测结果,λ1为同义词先验的正则化参数,θ0为当前训练epoch训练T1后的任务T1的参数。第二项是加强目标词xt与其已知同义词之间的词嵌入相似性,第三项是连续的正则化项,以稳定训练过程。
设φI = [VxI, fT 1(xI)]。定义在xI和fT 1(xI)条件下观察单词xO的概率为
.jpg)
公式(5)中的一个问题是计算归一化因子的复杂性很高,因为它涉及到对词汇表中所有单词的求和。为了解决这个问题,我们使用了负采样(NEG)[24]将原始的一对所有多类目标转换为二分类目标。对于负采样,公式(5)的负对数可以改写为:
.jpg)
式中Pneq(xj)为xj的负样本集。将Eq.(6)代入Eq.(4),我们得到任务T2的简化目标:
.jpg)
3.3 训练
模型在一个外部知识库支持的大型文本语料库上训练,该语料库提供语义类型和术语-术语同义关系。我们使用小批量随机梯度下降(SGD)与一个计划,以衰减一半的学习率后,特定的全局步骤。
在每个epoch期间,优化从较低的任务迭代到较高的任务,如图2所示。具体来说,我们首先最小化Eq.(3)中的LT 1,在整个训练集上更新V和U,然后将优化后的V和U传递给上。通过在整个训练集上最小化Eq.(7)中的LT 2,我们更新W,V和U,并在下一个epoch开始时将V传递给较低级别任务。我们重复上述过程,直到达到预定义的纪元数,并输出V作为最终的单词嵌入。
之所以选择V而不是W作为最终的嵌入,是因为V是两个任务共享的,两个任务都会更新,而W只在训练相邻的单词预测任务时更新。因此,V携带更多关于实体类型的语义信息。我们也尝试使用w作为最终的嵌入,但它没有显示任何改进。
3.4 应用到同义词预测
在词汇嵌入学习中,虽然使用了同义词关系,但同义词的覆盖面有限。为了提取更多的同义对,可以训练更复杂的模型,或者使用简单的模型(例如线性支持向量机[6]),但包含更多信息特征。在本文中,我们采用后一种方法,因为我们的重点是学习更多有代表性的嵌入。
为了获取更多对同义词抽取有用的信息,我们跟随Wang等人[32]为术语对构建特征,包括扩展嵌入和词汇匹配特征。此外,我们增加了两个特征,1)词向量对之间的余弦相似度,2)两个词在字符串级之间的Jaro Winkler相似度[33],在实体名称匹配任务[2]中获得了最好的性能。
4 实验
我们从9种教材、医学维基a +医院[1]和医学问答论坛2中收集了中文医学语料库。总的来说,语料库包含大约1000万个句子。我们遵循UMLS实体类型分类法3,但将低级语义类型合并到其高级概念(例如,详细的药物成分到药物),并重命名几个语义类型,使众包验证更容易。共有18个类型:症状、疾病、药物、食物、治疗、手术、预防、医疗器械、科室、病因、身体部位、外伤、生物化学、检查及医学指标、生理学、心理学、医学调节、微生物学。
4.1医疗实体和同义词收集
在医疗维基网站上,我们收集了70K个专业实体。为了确定非正式医学术语,我们使用众包收集了30K份非正式医学描述。在200K个句子上训练由[36]实现的著名命名实体识别模型CNN-BiLSTM-CRF[21],其中初始的100K个医学术语在BIOES方案[3]下进行标注。由于有18种语义类型,我们总共有73个NER标记。在另外的20K个有标签测试句子上,我们获得了90.7%的F1得分。
利用训练后的NER模型,我们从包含10M句子的大型医学语料库中发现了58K个新的实体和短语。经过众包验证后,我们保留了51K,并将它们与最初的100K合并,构建了一个包含属于18种语义类型的151K实体的医学词典。在图3中,我们提供了医学词典的汇总统计信息。
.jpg)
使用dbscan的原因是它不需要指定集群的数量,可以找到任何形状的集群。我们将两个样本在同一邻域内的距离阈值设定为较小的阈值ε = 2,将一个样本作为核心点的最小样本数设定为minPoint = 3。较小的距离阈值将有助于减少误报,达到更高的精度。
在获得同义词集群(30K)后,我们使用众包来保证每个集群只包含高质量的同义词。我们将所有注释者分成几个组,让两组人对同一批数据进行标注。对于分歧,第三组做出选择。平均注释器协议为0.80 0.09。我们总共得到185K个同义对。
4.2 实验数据处理
为了准备词嵌入的训练数据,我们使用了我们的医学词典定制的知名中文分词工具jieba4,将医学文本语料库中的句子切割成单词和实体/短语序列。这样的程序将确保词嵌入算法将医学术语作为一个整体来处理,并学习它们的表示。通过过滤出现次数少于5次的生僻词,并去除标点符号,我们得到了411,256个唯一的单词和短语。我们将分割后的语料库分为3部分:80%的训练、10%的验证和10%的邻近语义类型预测实验。
在所有同义词对中,我们首先在第4.4小节中抽取包含3586个唯一实体的25k对样本进行实体语义相关性评估。其余160k对进一步分割为80%、10%、10%,用于4.6小节中同义词预测实验的训练、验证和测试。同义词对的80%分割也被用作我们的词汇嵌入训练的术语-术语知识。在表3中,我们总结了数据集的特征。
.jpg)
4.3 实验参数设置
我们将单词向量长度d设为200,初始学习率设为0.001,相邻窗口大小设为5,小批量大小设为400,epoch数设为20,负样本数设为20。
找到最好的hyper-parameters我们的模型,我们运行一个参数搜索的组合连续正则化参数λ={0.1,0.5,1、2、8}和同义词前正规化λ1 ={0.01,0.05,0.1,0.5,1},和计算的平均双向余弦相似性的一对dev数据。我们发现这些参数并没有显著地改变性能(最多1.0%)。我们设定λ = 0.5和λ1 = 0.05,得到最佳结果。
为了公平比较,我们在80%的语料库数据(8M句)和术语-术语同义关系数据上对每种方法(我们的和竞争的方法)进行训练。此外,每种方法在单词向量长度、小批量大小、负样本数量和纪元数量方面都具有相同的设置。
我们将我们的方法与几种最先进的词嵌入方法进行了比较。
miolov et al.[23]。我们使用gensim package5训练一个具有与我们方法相同配置的skip-gram模型。
Yu和Dredze[37]。我们使用它们的联合模型训练代码6训练单词向量,使用与上面相同的设置。黄金同义词的80%被用作释义DB输入。C是默认设置。
Wang et al.[32]。该方法在训练过程中只使用语义类型信息,没有其他超参数需要调优。由于这个方法没有开放源码的实现,我们小心地在Tensorflow中实现它以进行比较。
Faruqui等,[7]。本文的改进算法是一种使同义词对的词向量更加相似的后处理方法。我们使用源代码7,并将其应用到Mikolov等人[23]的单词vectors上。语义图由黄金同义词的80%分割(128K)构成。
w2vRegSTL。我们的方法的一个单任务版本,它只保持邻近词预测任务在上层。
4.4 实体语义关系评估
:right_anger_bubble: 2万5个同义词对(包括了3586个独立实体)是什么样的?
这种评估是在不训练任何监督模型的情况下,以直接的方式测试学习的单词/短语表示的质量。在所有度量中,一对词向量之间的余弦相似度通常用于量化两个词的相似程度。但是,由于每种方法学习的单词嵌入空间不同,直接比较所有方法的余弦值是不合适的。相反,我们根据每个实体的余弦相似度来比较其排名前k的实体的精度。
具体来说,给定每种方法对应的实体,首先计算语义相关度评价对数据中输入实体与其余实体之间的余弦相似度,然后对它们进行降序排序。由于已知输入的评估数据中的真实同义词,我们可以计算precision@k = tp/k,其中tp是输入实体中排名最高的k个实体中的真实同义词数量。
.jpg)
表4 求k = 1,3,5时precision@k的平均值。粗体表示最好的性能。用*标记的单元格表示我们的方法显著优于(p <0.05)所有比较方法。
在表4中,我们报告了语义相关性评估数据中唯一的3586个实体的平均precision@k。从表中,我们观察到原始的skip-gram模型表现最差,这是合理的,因为它没有利用任何语义知识。虽然Wang et al.[32]利用了语义类型信息,但其性能略好于Mikolov et al.[23],但仍低于那些使用同义关系的方法。Faruqui等人的[7]嵌入训练后的后处理方法比Yu和Dredze[37]和w2vRegSTL表现更差,后者利用了相同的术语-术语同义词关系,但在训练时使用了它们。
我们怀疑一个可能的原因是Faruqui等人[7]只使用了训练同义词对,而训练同义词对可能与测试同义词数据重叠较少。在这种情况下,即使Faruqui等人[7]在训练数据中强制平滑同义词对,但对遗漏数据中的术语没有影响。对于contrary, Yu和Dredze [37], w2vRegSTL和我们提出的方法不仅从同义关系中迭代学习嵌入,而且从文本中迭代学习,这将允许两个孤立项之间的相似性通过一些中间项传播。
最后,我们提出的多任务方法在t检验(p<0.05)下的统计显著性优于所有基线,这证明了同时利用语义类型和同义词知识以及分层安排两个任务的好处。
4.5 语义类型预测评估
:right_anger_bubble:10%的数据集语料库是什么样的?
由于我们在skip-gram模型中引入了辅助任务邻词语义类型预测,因此我们的框架在该任务中的有效性值得研究。
为了比较,我们固定来自竞争方法的所有单词向量,并训练相同的二元关联模型(如Eq.(3)所述),除了将连续正则化项替换为参数U的L2范数惩罚。
.jpg)
表5 邻近词语义类型预测任务的AUC评分。MacroAUC为宏观平均AUC, MicroAUC为微观平均AUC
表5显示了18种语义类型的微观平均和宏观平均AUC得分。我们观察到Wang等人[32]的表现比其他方法差得多。其余的基线相互之间的行为相似。我们的方法再次获得了约80% AUC的最佳结果,这表明了联合学习相关任务的重要性。
4.6 同义词预测的评估
:right_anger_bubble:16万的同义词对
由于本文的重点是学习更好的同义词预测医学实体/描述表示,我们使用线性分类器[6]而不是复杂的分类器来证明学习嵌入的效用。如3.4小节所述,我们同时提取扩展的嵌入特征和语法相似特征,每对术语共1406个特征。为了进行公平的比较,我们使用相同的特征构建程序,并对所有竞争方法运行相同的分类器。
为了构建负样本,我们从字典中随机抽取了1.4万对医学术语。这样的程序可能会导致假阴性,但由于术语数量相对较多,这种可能性很小。我们将1.4M的负样本分别分割成80%、10%、10%,并结合表3所示的真实同义词对进行训练、验证和测试数据。我们在LIBLINEAR包[6]中使用L2正则化logistic回归,并在F1度量上的验证数据上调优{0.01,0.1,0.5,1,4,16,64,256}中的超参数。根据训练数据(1.4M/160K)中正负样本比的倒数,将正样本权值设置为8.75。
.jpg)
表6所有方法对测试数据的精度、召回率和F1分数。用*标记的单元格表示我们的方法显著优于(p <0.05)所有基线。
表6显示了测试数据的精度、召回率和F1分数。我们首先观察到,所有的方法都有一个相对较高的查全率比精度,这是由于积极的类别权重。实际上,在真实的应用程序中,可以调整不同的样本权重和预测阈值,以在精度和召回率之间进行权衡。Wang等人[32]的结果表明,在同义词预测任务中,术语-术语同义关系比语义类型知识更重要。我们的方法利用了语义类型信息和术语术语同义词知识,在比例检验(p-value<0.05)的统计显著性下,在所有三个指标上取得了最好的性能。
为了了解我们完整模型的每个组成部分对同义词预测的贡献,我们进行了消融研究,并报告了每个组成部分失效时的F1评分,如表7所示。
.jpg)
去除邻近词语义类型预测和同义正则化的辅助任务后,模型性能分别显著恶化2.09%和1.14% (p <显著统计t检验;0.01)。如此巨大的性能下降说明了引入辅助任务和合并同义词知识的重要性。此外,禁用两两的词汇匹配特征会略微降低预测性能,这与Wang等人[32]一致。
4.7 未标记的同义词对应用
:right_anger_bubble:未标记的同义词对
在医学领域,由于用户对同一概念有不同的表达方式,语言使用的高变异性往往源于症状术语。为了生成更多的同义对,我们将训练好的同义模型应用到我们收集的同义数据中从未出现过的400M症状对上,获得了大约1M的新同义对。虽然没有办法彻底验证新生成的配对的准确性,我们执行手动验证,遵循实体语义相关性评估的类似程序。
首先,我们随机选择200个症状作为查询,并根据概率评分收集每个症状的前5名同义词,然后手工标记每个词是否是查询实体的真实同义词,并计算precision@k的度量。最后,我们计算平均值precision@k并报告结果,如图4所示。与表6相比,精度有所下降。可能的原因是,我们只从未标记的数据中抽取彼此非常相似的症状对,这比无论语义类型如何随机抽样更具挑战性。尽管如此,我们的模型在k=3时仍能达到73%的精度。
.jpg)
首先,我们随机选择200个症状作为查询,并根据概率评分收集每个症状的前5名同义词,然后手工标记每个词是否是查询实体的真实同义词,并计算precision@k的度量。最后,我们计算平均值precision@k并报告结果,如图4所示。与表6相比,精度有所下降。可能的原因是,我们只从未标记的数据中抽取彼此非常相似的症状对,这比无论语义类型如何随机抽样更具挑战性。尽管如此,我们的模型在k=3时仍能达到73%的精度。
.jpg)
4.8 错误分析
我们还仔细分析了在我们的手工验证中发现的一些典型错误,以指导未来的研究。在表8中,我们列出了8个症状术语及其前5个最同义的术语,其中假阳性用粗体突出显示。
从表中,我们观察到,尽管我们的方法可以成功地联系一些语义相同但词汇方面不同的描述,例如,例假特别少很多头皮屑vs。经量很小(少出血期间)和老是尿尿(非常尿频)vs小便很频(非常尿频),有几个限制,以防止所提出的方法工作的完美。
- 无法分辨出有非常相似词汇模式的身体部位。例如,小肚(腹部)和小腿肚(小腿)只有一个字符不同,但他们是指不同的身体部位。为了减少这种错误,可以开发一个主题匹配模块,在应用同义词预测模型之前检测两个短语是否共享同一个主题。
- 没有区分同义词和语义关联。尽管词嵌入已经捕获了一定程度的语义相关性,但要分辨同义词和语义相关性之间的区别并不总是可靠的,特别是对于词汇和语义都相关的词对。例如,胸部痛(胸痛)和胸部胀(胸部肿胀)经常同时发生,和他们的相互嵌入的非常相似,因此预计是同义的。为了减少这种误差,需要更多高质量的负样本覆盖这些情况,以指导分类器学习细微的差异。
- 感觉不到位置的差异。例如,肚脐周围疼痛(肚脐周围疼痛的区域)和肚脐右边疼(肚脐右边疼痛)属于同一概念肚脐疼(小说的痛苦),但有不同的位置。严格地说,他们不是同义的一对。为了缓解这一问题,需要更多的这类负样本,可以提取位置特征副词来学习位置差异。
5 总结
我们提出了一个分层的多任务词嵌入模型,以学习更多有代表性的医学实体嵌入,并将其应用于医学同义词预测。该模型通过引入邻词语义类型预测辅助任务,充分利用医学领域的知识,通过实体语义相关性、邻词语义类型预测和同义词预测,得到了更有语义意义的词表示。虽然我们的模型是为医学领域开发的,但它也可以应用到外部知识巨大、语言使用变异性非常高的其他领域。此外,我们还建立了一个包含实体注释、描述和同义词对的大型中文医学文本语料库,为今后在这一方向上的研究提供了参考。
未来的工作包括将该模型应用于其他语言的医学领域,并探索一个端到端的框架来集成单词表示学习和同义词预测。